
智能识别:单链DNA传感器阵列揭秘牛奶中的致病菌


1. 引言
食源性疾病因致病菌污染食品引发,对全球公共卫生构成重大威胁。传统检测方法如平板计数法虽为金标准,但存在流程复杂、耗时长且需无菌环境等局限;ELISA和PCR技术虽缩短检测时间,却受限于单病原体检测模式及高昂成本。传感器阵列技术通过分析细菌表面特征突破传统"锁钥原理"限制,利用二维纳米材料(如纳米氧化石墨烯、硫化钼等)构建生物传感器。这些材料凭借纳米级厚度、大比表面积及优异水稳定性,可高效吸附单链DNA形成竞争性结合-释放机制,实现多病原体同步检测。相比传统方法需10⁶ CFU/mL浓度阈值,该技术具备高灵敏度、实时响应优势,适用于复杂食品基质检测。最新研究已证实其在血清、尿液中识别致病菌的有效性,并展现出食品样品检测的应用潜力,为开发经济高效的食品安全监测系统提供新方向。
本研究报道了一种二维纳米颗粒和单链DNA的传感器阵列来识别真实食品样品中的八种致病菌和腐败菌。选择了五种因其在食源性疾病爆发中的流行而闻名的致病性细菌物种,以及三种非致病性腐败细菌物种。由于牛奶在室温下极易腐烂,因此被选为模型食品基质。从传感器阵列获得的数据经过预处理,然后使用六个机器学习(ML)模型进行细菌分类分析。这些ML模型的性能在不同的培养时间进行了比较,提供了对其有效性的全面评估。这项研究旨在证明将先进的纳米材料与机器学习技术相结合以增强食品安全监控的潜力。
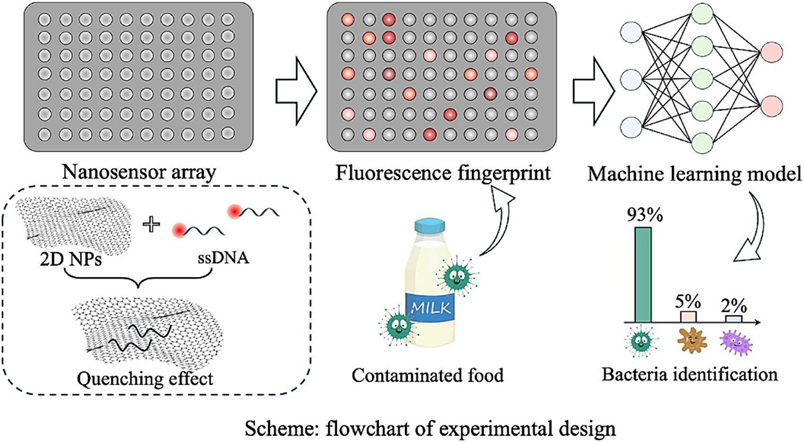
方案1. 实验设计流程图。
2. 结果与讨论
材料的表征
该研究通过超声剥离法结合插层剂胆酸钠处理,成功制备nGO、MoS₂和WS₂三种二维纳米粒子,形成单层/多层结构(厚度约5 nm,粒度分布246.3–2293.1 nm)。利用四种单链DNA(ssDNA)与上述纳米粒子构建12通道传感器阵列,通过优化荧光淬灭浓度(nGO:25 μg/mL,MoS₂:40 μg/mL,WS₂:80 μg/mL)实现90%以上ssDNA荧光猝灭。实验表明,添加大肠杆菌悬液后,传感器在80分钟内荧光强度恢复约60%,并基于时间梯度(30分钟至14小时)建立动态响应曲线。研究进一步验证了八种细菌的荧光响应模式一致性,确认传感器阵列在跨物种检测中的重复性(RSD<5%),为多病原体同步识别提供了高灵敏度(amol级)的检测平台。
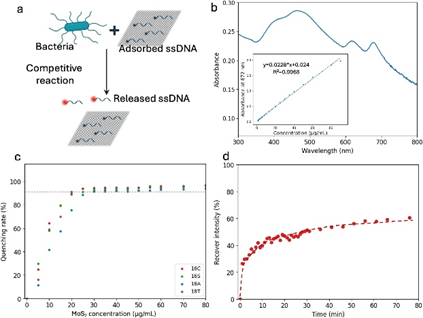
图1. 图1所示。(a)细菌与传感元件之间竞争反应的图示;(b) MoS2 NPs悬浮液的UV-Vis光谱;(c) MoS2和18a的淬火曲线;(d)大肠杆菌对mos2 - 18a的回收率曲线。
荧光恢复
实验记录了大肠杆菌在不同孵育时间(30分钟至14小时)的荧光响应。所有传感元件均呈现随时间增长的部分荧光恢复,30-120分钟呈渐增趋势,14小时后强度最大超10,000。30分钟时各元件响应值差异显著(数百至四千),源于细菌与ssDNA探针或纳米片表面的差异性相互作用导致的ssDNA解吸程度不同。

图2. (a)传感器阵列初始荧光强度;不同孵育时间(b) 30分钟,(c) 60分钟,(d) 90分钟,(e) 120分钟,(f) 14小时,引入大肠杆菌后的荧光强度。
研究发现,每种细菌在传感器阵列中表现出独特的荧光恢复模式,这与其表面微环境和组成结构有关[3]。八种细菌的标准化荧光模式显示出良好的重复性和一致性,轻微差异可能由环境因素如背景蛋白引起。传感器阵列对干扰物质(如高钠环境、蛋白质、葡萄糖和食品添加剂)表现出强抗干扰能力,荧光模式与任何细菌种类不同,确保了检测的准确性。
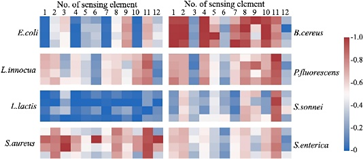
图3. 8种细菌在30 min孵育后的荧光强度。
主成分分析
PCA是一种常用的无监督算法,用于可视化高维数据。通过绘制12个传感元件的归一化数据,PCA揭示了数据差异的主要来源。前三个主成分解释了78.3%的方差,数据点根据细菌种类聚类成八组。然而,PCA未能有效地分离所有数据点,尤其是某些细菌种类之间存在重叠。因此,PCA通常用于特征提取,然后结合其他机器学习算法(如SVC和RFC)进行进一步分类,以提高分类精度。

图4. 细菌种类主成分分析(PCA)评分图,95%置信度椭球。
机器学习
为了优化机器学习模型的性能,需要仔细调整超参数。PLSDA和KNN模型相对简单,只需调整少量变量,如KNN的邻居数量和PLSDA的组件数量。SVC和RFC模型则使用网格搜索进行超参数调优,通过交叉验证评估预测性能。测试结果显示,SVC、KNN和RFC模型在测试集上的准确率超过80%,但未达到90%。这种有限的精度限制了传统机器学习模型在非特异性传感器阵列中的应用。
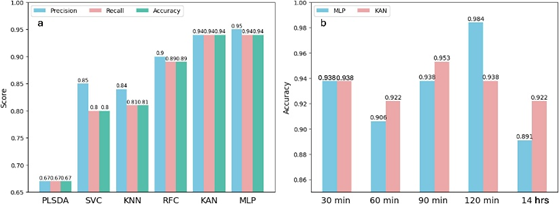
图5. (a) 6个模型在30分钟孵育下的分类性能,包括精度、召回率和准确率;(b)测试两个人工神经网络在不同时间持续时间下的准确率。
人工神经网络
Kolmogorov-Arnold网络(KAN)被提议为多层感知器(MLP)的替代方案。KAN在边(权重)上使用可学习的激活函数,而MLP在节点(神经元)上使用固定的激活函数。与MLP相比,KAN的参数数量显著减少(1736个vs. 10760个),且计算成本较低。实验结果显示,KAN和MLP在测试集上的准确率均高于93.75%,且KAN在某些时间段(60分钟、90分钟和14小时)的表现优于MLP。尽管KAN的损失和精度曲线波动较大,但其作为MLP的竞争性替代方案的潜力得到了验证,尤其是在参数效率和计算成本方面。最近的研究还提出了改进的KAN模型,如FastKAN和FasterKAN,进一步增强了其作为替代品的潜力。
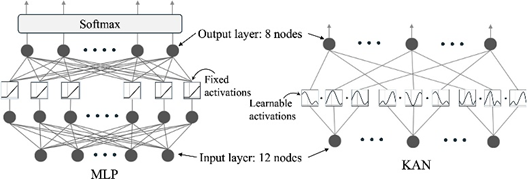
图6. 多层感知器(MLP)和Kolmogorov-Arnold网络(KAN)结构。对于MLP,有三层:输入层、隐藏层(512个节点)和输出层。隐藏层和输出层的激活函数为ReLU和Softmax。对于KAN,它包含输入和输出层。激活函数是基于样条的函数。
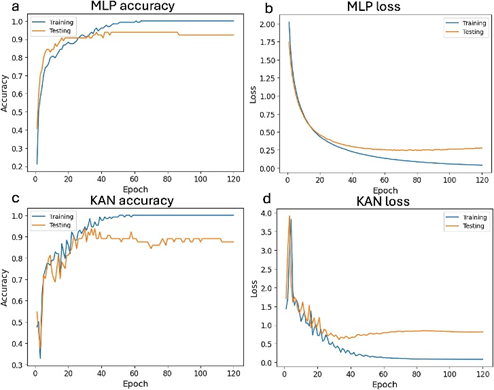
图7. 多层感知器(MLP)和Kolmogorov-Arnold网络(KAN)在训练集和测试集上的精度和损失曲线。

图8. 6个ML模型孵育30分钟后测试集上的混淆矩阵。
3. 总结
究人员成功开发了一种非特异性传感器阵列,用于识别真实食品样本中的致病性和非致病性腐败菌,整体准确率达到93.75%。当细菌悬浮液被引入传感器阵列时,每种细菌都会形成独特的指纹,通过回收的荧光值进行分类。虽然PCA无法有效分类八种细菌,但随机森林分类在30分钟后达到了90%的准确率,是传统机器学习模型中最好的。KAN和MLP神经网络在30分钟内也达到了93.75%的准确率,延长孵育时间到120分钟后,MLP的准确率提升至98%。这种非特异性传感器阵列方法展现了在实际食品样本中鉴定多种细菌的潜力,具有低成本和高准确性的优势。然而,考虑到目前采样方法的侵入性,未来改进可以专注于开发非接触式纸比色阵列,以便于操作和观察。
论文链接:https://doi.org/10.1016/j.foodchem.2024.141115
1、凡本网所有原始/编译文章及图片、图表的版权均属微生物安全与健康网所有,未经授权,禁止转载,如需转载,请联系取得授权后转载。
2、凡本网未注明"信息来源:(微生物安全与健康网)"的信息,均来源于网络,转载的目的在于传递更多的信息,仅供网友学习参考使用并不代表本网同意观点和对真实性负责,著作权及版权归原作者所有,转载无意侵犯版权,如有侵权,请速来函告知,我们将尽快处理。
3、转载请注明:文章转载自www.mbiosh.com
联系方式:020-87680942

